
探索数据缓存——LRUCache
今天介绍下数据结构中,一个新朋友——LRUCache
那什么又是LRUCache呢?
LRUCache
LRU是Least Recently Used的缩写,译为最近最少使用的,所以合起来意思是最近最少使用的缓存,它是一种Cache替换算法。注意这个东西是包含了数据结构和算法的。(称为最久未使用的缓存,小编觉得更形象)
那什么又是Cache呢?
狭义 的Cache指的是位于CPU和主存间的快速RAM。
广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度 差异的结构。
Cache不像内存那样有很多空间,所以,当Cache的容量用完后,而又有新的内容需要添加进来的时候,就需要挑选并舍弃原有的部分内容,从而腾出空间放新的内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。
那么在java中,类似这样的数据结构就是:LinkedHashMap
它呢是基于链表+HashMap实现的
为什么呢?
因为HashMap查找的时间复杂度是:O(1)
链表的插入和删除的复杂度也是比较快的,也是O(1),这里指的是头尾操作噢~
代码演示:
public static void main(String[] args) {
LinkedHashMap<String,String> map=new LinkedHashMap<>(16,0.75f,false);
map.put("1","100");
map.put("2","200");
map.put("3","300");
System.out.println(map);
}
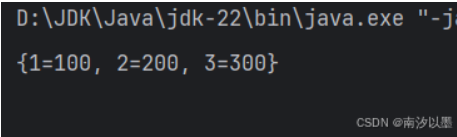
这里的三个参数代表什么意思呢?
initialCapacity:初始化容量大小,使用无参构造方法时,此值默认为16
loadFactor:加载因子,使用无参的构造方法时,此值默认为0.75f
accessOrder :false:基于插入顺序,true:基于访问顺序
基于插入顺序,那么就是按照插入的时候,按顺序打印。
如若我改为true呢?
public static void main(String[] args) {
Map<String,String> map=new LinkedHashMap<>(16,0.75f,true);
map.put("1","100");
map.put("2","200");
map.put("3","300");
System.out.println(map);
map.get("1");
map.get("2");
System.out.println(map);
}
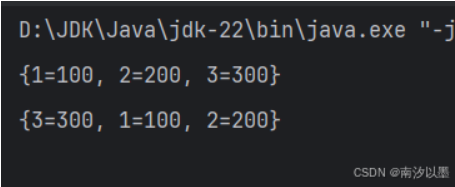
那么此时基于的是访问顺序,我们首先访问的是1,所以把1放到最后,
即访问谁,就把谁放到最后。
还有值得注意的是,如若我们放入的个数是大于了我们默认给定的初始值,那么就会删除头节点,然后再把新插入节点放入到尾节点去。
代码效果:
public class Test<k,v> extends LinkedHashMap<k,v> {
public int capacity=0;
public Test(int capacity){
super(capacity,0.7f,true);
this.capacity=capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size()>capacity;
}
public static void main(String[] args) {
Test<String,String> map=new Test<>(3);
map.put("1","100");
map.put("2","200");
map.put("3","300");
System.out.println(map);
map.put("4","400");
System.out.println(map);
}
}
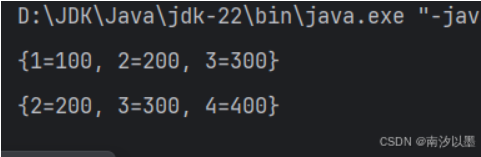
那么接下来小编带着大家来实现下其中的一些方法吧
实现LRUCache
那么这里要说明的是,底层的链表是自己实现,而这个HashMap,则是使用库里的即可
而链表的实现过程是基于accesOrder==true。即是访问顺序
1.初始化
这里的构造的链表是带头双向链表,便于高效的管理,因为涉及到删除和插入操作
节点的定义
static class DListNode{
public int key;
public int val;
public DListNode next;
public DListNode prev;
public DListNode(){
}
public DListNode(int key,int val){
this.val=val;
this.key=key;
}
@Override
public String toString() {
return "{ key = "+ key +"," + " val = " + val +" } ";
}
}
这里重写toString方法是为了后续实现print方法的
//设置两个头尾哨兵节点
public DListNode head;
public DListNode tail;
//使用本地库中的Map方法
public Map<Integer,DListNode> map;
//有效数据有多少个
public int Usize;
//初始化给定容量
public int capacity;
public MyLRUCache(int capacity){
this.head=new DListNode();
this.tail=new DListNode();
head.next=tail;
tail.prev=head;
map=new HashMap<>();
this.capacity=capacity;
}
这里设置带头的链表,是为了后续插入节点不需要判断头节点是否为空的,便于操作。
然后,HashMap是使用了java库的类。
2.put方法
实现思路:
首先,判断插入的数据中,是否存在了Map中
没有意味着是第一次插入
1.首先实例化一个节点
2.然后存在Map中
3.插入尾巴节点
4.然后判断下usize 是否大于capacity,如果大于,那么就要进行删除头节点操作,删除节点之前,先删除Map里保存的信息
如若有,那么此时就要更新此val值
然后移动节点到尾巴节点去
public void put(int key,int val){
//首先,判断插入的数据中,是否存在了Map中
DListNode node=map.get(key);
if(node==null){
//没有意味着是第一次插入
//1.首先实例化一个节点
DListNode dListNode=new DListNode(key,val);
//2.然后存在Map中
map.put(key,dListNode);
//3.插入尾巴节点
Addtotail(dListNode);
Usize++;
//4.然后判断下usize 是否大于capacity,如果大于,那么就要进行删除头节点操作
if(Usize > capacity){
//移除Map里的信息
DListNode retNode=removeHead();
map.remove(retNode.key);
Usize--;
}
}else{
//有,说明是要更新val值
//1.更新val值
node.val=val;
//2.移动该节点到尾巴节点去
MoveTotail(node);
}
}
private void MoveTotail(DListNode node) {
//移动操作
//1.删除此节点在此处的位置
removeNode(node);
//2.移动位置到尾巴节点
Addtotail(node);
}
private void removeNode(DListNode node) {
node.prev.next=node.next;
node.next.prev=node.prev;
}
private DListNode removeHead() {
DListNode delNode=head.next;
head.next=delNode.next;
delNode.next.prev=head;
return delNode;
}
private void Addtotail(DListNode Node) {
tail.prev.next=Node;
Node.prev=tail.prev;
Node.next=tail;
tail.prev=Node;
}
这里给到一个示例模板,望读者可自行推导下节点移动过程~
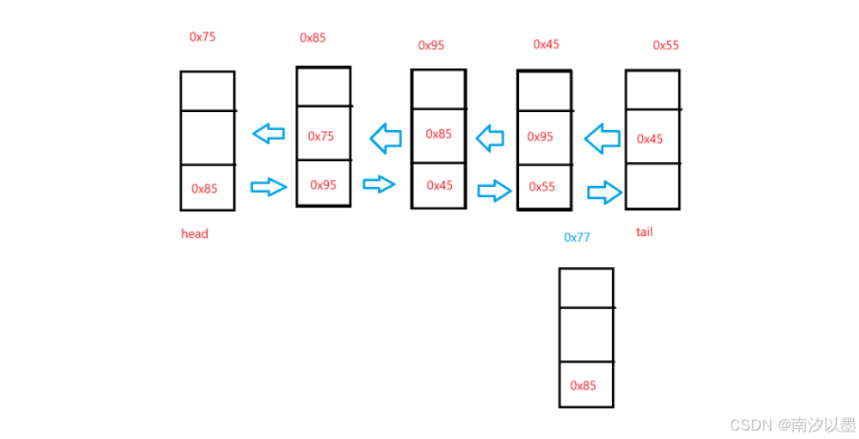
3.get方法
public int get(int key){
//get操作是将获取到的节点,使其变成最常使用的节点,放进尾巴节点中
DListNode listNode=map.get(key);
if(listNode == null){
return -1;
}
MoveTotail(listNode);
return listNode.val;
}
注意,如若访问的节点是null的,所以此时可以要返回一个-1,或者抛出一个异常提醒
4.print方法
实现此方法是为了方便打印其内部的值
因为节点类已经实现了这个toString方法,所以此时实现起来就方便了
就是遍历链表即可
public void print(String str){
System.out.println(str+":");
DListNode listNode=head.next;
while (listNode!=tail){
System.out.print(listNode+" ");
listNode=listNode.next;
}
System.out.println();
}
源码:
public class MyLRUCache {
static class DListNode{
public int key;
public int val;
public DListNode next;
public DListNode prev;
public DListNode(){
}
public DListNode(int key,int val){
this.val=val;
this.key=key;
}
@Override
public String toString() {
return "{ key = "+ key +"," + " val = " + val +" } ";
}
}
//设置两个头尾哨兵节点
public DListNode head;
public DListNode tail;
//使用本地库中的Map方法
public Map<Integer,DListNode> map;
public int Usize;
public int capacity;
public MyLRUCache(int capacity){
this.head=new DListNode();
this.tail=new DListNode();
head.next=tail;
tail.prev=head;
map=new HashMap<>();
this.capacity=capacity;
}
public void put(int key,int val){
//首先,判断插入的数据中,是否存在了Map中
DListNode node=map.get(key);
if(node==null){
//没有意味着是第一次插入
//1.首先实例化一个节点
DListNode dListNode=new DListNode(key,val);
//2.然后存在Map中
map.put(key,dListNode);
//3.插入尾巴节点
Addtotail(dListNode);
Usize++;
//4.然后判断下usize 是否大于capacity,如果大于,那么就要进行删除头节点操作
if(Usize > capacity){
//移除Map里的信息
DListNode retNode=removeHead();
map.remove(retNode.key);
Usize--;
}
}else{
//有,说明是要更新val值
//1.更新val值
node.val=val;
//2.移动该节点到尾巴节点去
MoveTotail(node);
}
// print("put");
}
public int get(int key){
//get操作是将获取到的节点,使其变成最常使用的节点,放进尾巴节点中
DListNode listNode=map.get(key);
if(listNode == null){
return -1;
}
MoveTotail(listNode);
// print("get");
return listNode.val;
}
/**
* 未超出容量时移动尾巴节点
* @param node
*/
private void MoveTotail(DListNode node) {
//移动操作
//1.删除此节点在此处的位置
removeNode(node);
//2.移动位置到尾巴节点
Addtotail(node);
}
/**
* 未超出容量删除节点
* @param node
* @return
*/
private void removeNode(DListNode node) {
node.prev.next=node.next;
node.next.prev=node.prev;
}
/**
* 超出容量删除头节点操作
* @param
*/
private DListNode removeHead() {
DListNode delNode=head.next;
head.next=delNode.next;
delNode.next.prev=head;
return delNode;
}
/**
* 新节点插入尾巴节点
* @param Node
*/
private void Addtotail(DListNode Node) {
tail.prev.next=Node;
Node.prev=tail.prev;
Node.next=tail;
tail.prev=Node;
}
public void print(String str){
System.out.println(str+":");
DListNode listNode=head.next;
while (listNode!=tail){
System.out.print(listNode+" ");
listNode=listNode.next;
}
System.out.println();
}
}
{kind=link}
{kind=link}